前準備
データを準備
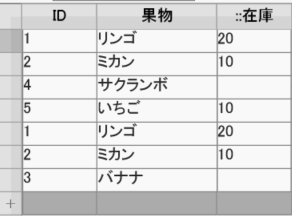{kind=link}
上の図のようなIDと果物が重複したデータを準備しました。
これを、下記の図のように、
ココがポイント
重複しないデータにしたい!
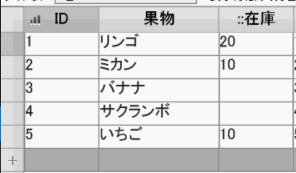{kind=link}
大量の重複したデータがあったとして、それをグループ化して集計するときなどに必要とすると思う。
フィールドを準備
重複をグループ化させるのに、3つのフィールドを準備しました。
「重複ID」「重複チェック」「カウンタ」
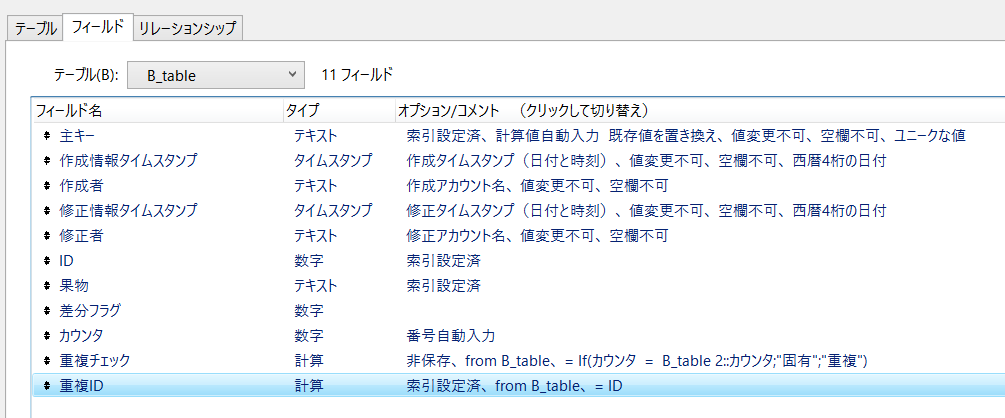{kind=link}
自己リレーションにする
そして、リレーションを「重複ID」で自己リレーションにします。
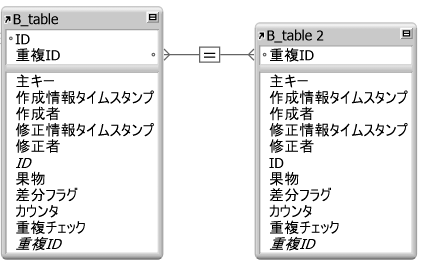{kind=link}
動作確認(重複チェック)
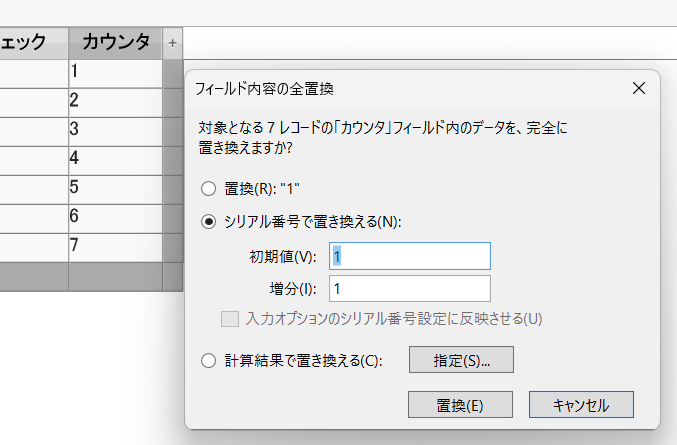
カウンタフィールドにカーソルを持っていき、メニューバーから、「フィールド内容の全置換」にて、「カウンタ」に連番を振りました。
{kind=link}
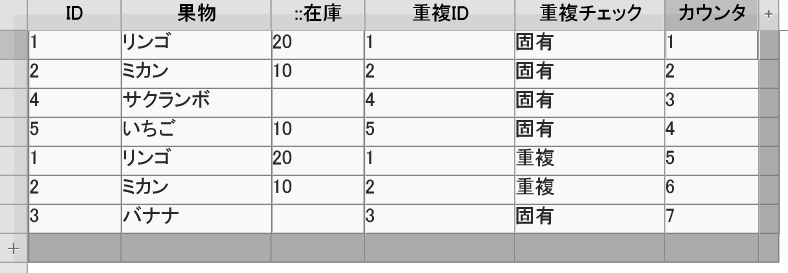
それと同時に、「重複チェック」フィールドには、「固有」か「重複」かの判定表示がされました。
{kind=link}
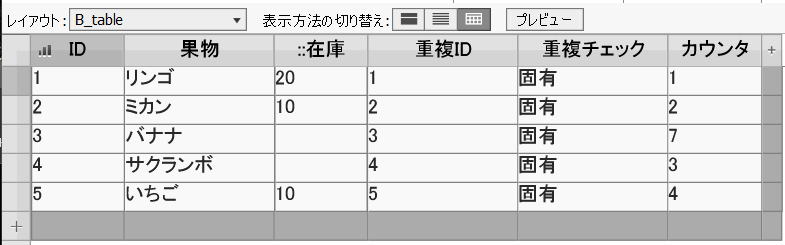
これを、「固有」で検索かければ求めるレコードだけの表示になりました。
{kind=link}
とりあえず、「ID」は昇順でソートかけて見栄えも良くしてみました。
データを追加する度にカウンタ更新
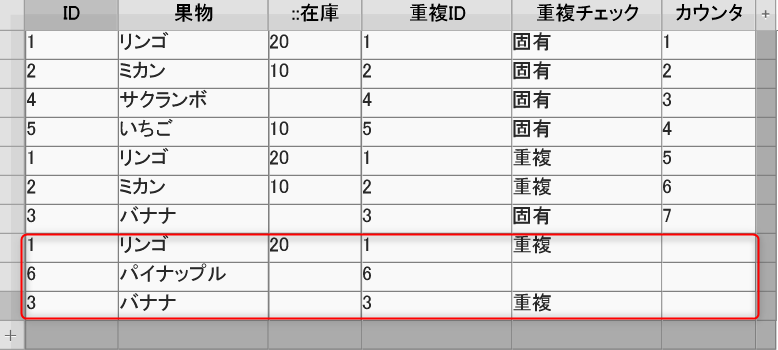
新規レコードを追加するとどうなるのかを実験しました。
{kind=link}
「カウンタ」の自動連番入力機能は関係ないようなので外しました。
その後新規で入力すると、カウンタが入ってないので「重複チェック」の判定が重複か空欄になりました。
「フィールド内容の全置換」を実行して採番をすると判定結果がでました。
注意ポイント
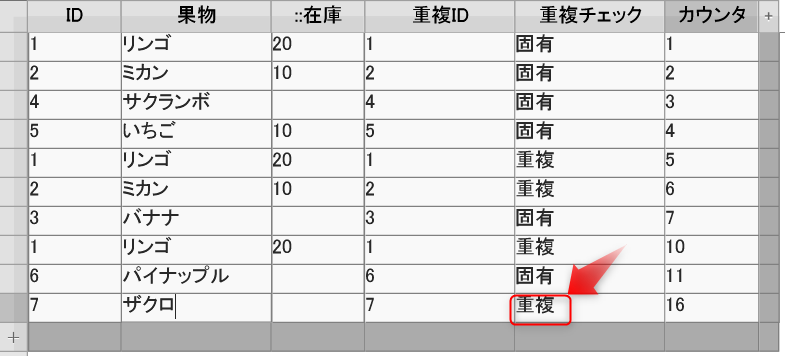
では、「カウンタ」を自動連番にしておけば、「フィールド内容の全置換」を実行しなくてもいいのでは?
{kind=link}
新規で重複しないレコードを追加しましたが、「重複チェック」が「重複」になっています。
この時点では、レコードが確定されてなかったようで、他のレコードにカーソルを持っていったら「固有」になりました。
ココがポイント
「カウンタ」を自動採番にしておけば、「フィールド内容の全置換」を実行しなくてもOK
どういう原理
{kind=link}
なんか理解できませんでしたが、よーく考えて見るとなるほどとなりました。
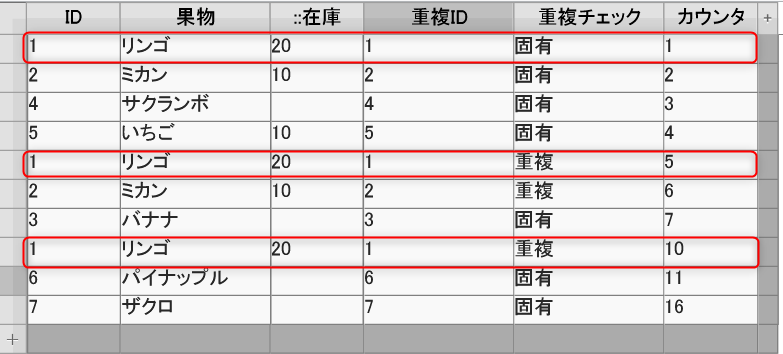
1回目 ID(1):重複ID(1):カウンタ(1) 固有
2回目 ID(1):重複ID(1):カウンタ(5) 重複
3回目 ID(1):重複ID(1):カウンタ(10) 重複
IDと重複IDが同じなのに、カウンタが違う場合は重複と見なしている。
ちなみに、手動で、2回目のカウンタ(5)をカウンタ(1)にすると、固有になりました。
カウンタはダブりのない連番でないと正確な判定ができないという事ですね。
FileMakerに、もっと簡単なグループ化的な機能があると良かったのですが、この方法で何とかできるので良しとする。